
Table of Contents
- Introduction to Multiclass Classification Using Scikit-Learn
- Importance and Real-World Applications
- Key Components of Multiclass Classification
- Dataset Preparation and Exploration
- Data Splitting for Model Training
- Popular Algorithms for Multiclass Classification Using Scikit-Learn
- Decision Tree Classifier
- Support Vector Machine Classifier
- K-Nearest Neighbors Classifier
- Naive Bayes Classifier
- Model Evaluation Techniques
- Visualizing Classification Results
- Strengths and Weaknesses of Popular Multiclass Algorithms
- Practical Use Cases in Industry
- Best Practices for Building Better Multiclass Models
- Conclusion
- External and Internal Resources
1. Introduction to Multiclass Classification Using Scikit-Learn
Multiclass classification using scikit-learn refers to the supervised learning process in which a machine learning model is trained to differentiate between three or more categories. Unlike binary classification, where only two outcomes exist, multiclass classification accommodates more complex situations such as recognizing whether a flower belongs to one of several species or determining which category an image belongs to.
Scikit-learn is one of the most widely used Python libraries for machine learning. It provides ready-made implementations of major multiclass algorithms, along with tools for preprocessing, splitting datasets, evaluating model performance and visualizing outcomes. These features make scikit-learn a perfect choice for students, beginners and professionals developing predictive models.
2. Importance and Real-World Applications
Multiclass classification plays a vital role in data science, artificial intelligence and automation. Some real-world examples include:
- Identifying flower species from botanical measurements
- Categorizing images into different objects
- Classifying handwritten digits
- Sorting products into categories within e-commerce
- Predicting types of diseases based on medical test results
Every time a computer system assigns an item to one category out of many, multiclass classification is being used. Scikit-learn simplifies this work by offering reliable and optimized algorithms.
3. Key Components of Multiclass Classification
Multiclass classification using scikit-learn involves several essential components:
Features
These are measurable attributes used to describe each instance. In the classic Iris dataset, features include petal length, petal width, sepal length and sepal width.
Labels (Classes)
These are the names of the categories that the model aims to predict. For example, in the Iris dataset, the classes are setosa, versicolor and virginica.
Instances
Each row in the dataset corresponds to a single instance containing feature values and a label.
Understanding features and labels is critical for building accurate machine learning models.
4. Dataset Preparation and Exploration
Before performing multiclass classification using scikit-learn, the dataset must be loaded and understood. The Iris dataset is a classic benchmark dataset widely used for demonstrating machine learning. It consists of 150 rows of flower measurements with three distinct classes.
Each row includes four numeric features. The target variable represents the class label using integers such as 0, 1 and 2. These integers correspond to the three flower species. This simple structure makes it ideal for learning and teaching multiclass classification concepts.
Dataset exploration typically involves:
- Checking the shape of the data
- Understanding feature ranges
- Inspecting class distribution
- Observing relationships between numeric attributes
This step provides necessary insights before training any model.
5. Data Splitting for Model Training
A crucial process in multiclass classification using scikit-learn is dividing the dataset into training and testing portions. This ensures that the model is evaluated fairly and prevents overfitting.
Usually, 70% of the data is used for training and 30% for testing. A defined random seed is often used so that the split remains consistent across different runs. The training data helps the model learn patterns, while the test data evaluates how well it performs on unseen samples.
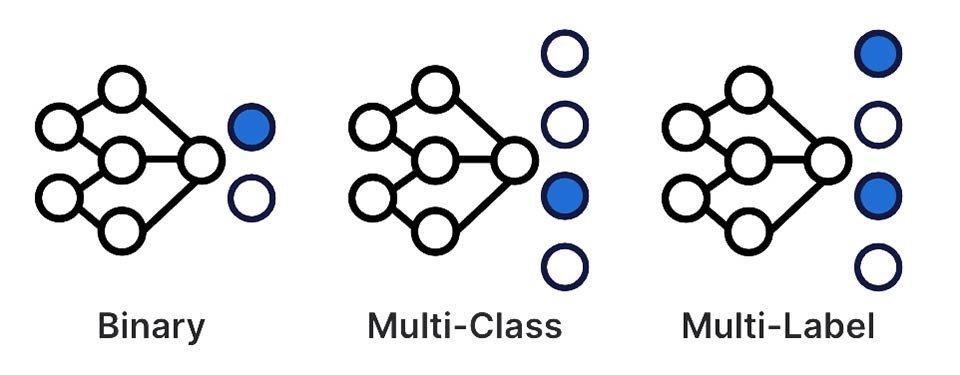
6. Popular Algorithms for Multiclass Classification Using Scikit-Learn
This section explains each classifier in a rewritten descriptive manner without using any code.
A. Decision Tree Classifier
The Decision Tree Classifier is a simple and interpretable model that builds a tree-like structure to make decisions. Each internal node represents a question based on a feature, and each branch corresponds to an answer. As the tree proceeds downward, instances are filtered based on these decisions until they reach a leaf node, which defines the class.
In multiclass classification, the decision tree divides the data so that each leaf node corresponds to one of the categories. It is easy to visualize and understand, making it a popular introductory algorithm.
Decision trees are effective when the dataset has clear boundaries between classes. However, shallow trees may underfit, while very deep trees can overfit.
B. Support Vector Machine (SVM) Classifier
The Support Vector Machine classifier aims to find the optimal boundary that separates multiple classes with the maximum margin. In multiclass classification using scikit-learn, SVM operates by creating separate boundaries for each pair of classes using a strategy such as one-vs-one or one-vs-rest.
A linear kernel is often used for simple datasets, but scikit-learn also offers other kernels for more complex boundaries. SVMs are known for producing high accuracy and stable performance, especially when the dataset is well-structured.
C. K-Nearest Neighbors (KNN) Classifier
K-Nearest Neighbors is a non-parametric algorithm that classifies a new instance by examining its closest neighbors in the training data. It counts how many neighbors belong to each class and assigns the class that appears most frequently.
This approach is intuitive, easy to understand and works well for smaller datasets. However, it can become slow when dealing with large datasets because every prediction requires searching through stored training samples.
D. Naive Bayes Classifier
The Naive Bayes classifier applies Bayes’ theorem to perform probabilistic classification. It assumes that features are independent given the class label, which simplifies computations. The Gaussian Naive Bayes variant is commonly used for datasets containing continuous values.
Despite its simplicity, Naive Bayes performs exceptionally well in many multiclass classification problems using scikit-learn. It is particularly strong when features behave independently or when the dataset is noisy.
7. Model Evaluation Techniques
Evaluating performance is an essential step in multiclass classification using scikit-learn. Two widely used methods include:
Accuracy Score
This metric measures the proportion of correct predictions. While accuracy is simple and easy to interpret, it may not provide a complete picture if the classes are imbalanced.
Confusion Matrix
The confusion matrix breaks down model predictions into categories such as true positives, false positives and false negatives for each class. It provides a detailed understanding of where the model performs well and where it makes mistakes.
Visualizing the confusion matrix helps reveal misclassification trends and provides valuable insights into model performance.
8. Visualizing Classification Results
Visualization plays a major role in understanding multiclass classification using scikit-learn. Confusion matrices, heatmaps and scatter plots make it easier to see patterns, class separations and errors.
An example image description (non-code) could be:
Image: Heatmap showing predicted versus actual class labels with the alt text “Multiclass classification using scikit-learn”.
Visuals make your content more engaging and help readers interpret classification results more effectively.
9. Strengths and Weaknesses of Popular Multiclass Algorithms
Decision Tree
- Strengths: Interpretable, easy to visualize
- Weaknesses: Overfitting risk
SVM
- Strengths: High accuracy
- Weaknesses: Sensitive to scaling and kernel choices
KNN
- Strengths: Simple, intuitive
- Weaknesses: Slower predictions on large datasets
Read Article on KNN for further detail
Naive Bayes
- Strengths: Fast, handles noise well
- Weaknesses: Independence assumption may not always hold
10. Practical Use Cases in Industry
Multiclass classification using scikit-learn is widely applied in:
- Customer product segmentation
- Medical diagnosis prediction
- Quality inspection in manufacturing
- Text classification and spam detection
- Image recognition
Its flexibility makes it a universal tool across domains.
11. Best Practices for Building Reliable Multiclass Models
- Normalize or standardize numeric features
- Perform feature selection if dataset is large
- Experiment with different algorithms
- Use cross-validation
- Visualize model performance
- Adjust hyperparameters to improve accuracy
12. Conclusion
Multiclass classification using scikit-learn is a powerful approach for solving predictive modeling problems involving multiple categories. With clear concepts, proper dataset preparation and appropriate algorithms, beginners and experts alike can build strong models that perform accurately on a wide range of tasks. This guide explained the complete process step by step, covering dataset understanding, algorithm selection, model evaluation and visualization.