
Table of Contents
- Introduction to K-Nearest Neighbour Algorithm
- How Does KNN Work?
- What Is “K” in K-Nearest Neighbour?
- Distance Metrics Used in KNN
- Step-by-Step KNN Algorithm Example
- Applications of K-Nearest Neighbour Algorithm
- Advantages and Disadvantages
- Best Practices and Resources
- Conclusion
Introduction to K-Nearest Neighbour Algorithm
The K-Nearest Neighbour Algorithm (KNN) is a supervised learning technique used widely in Machine Learning for classification and regression problems.
It predicts a label or value by finding the k closest data points to a new sample and making a decision based on majority voting or averaging.
Because it makes no assumptions about data distribution, KNN is known as a non-parametric and instance-based learning method — it learns “on the go.”
Fun fact: KNN is called a lazy learner because it stores the entire training data and performs calculations only during prediction time.
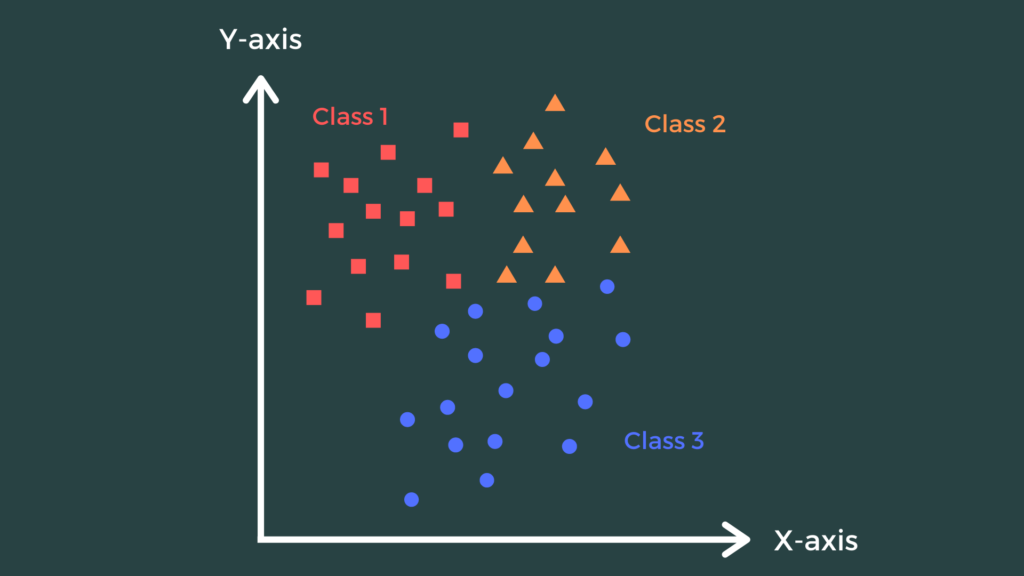
How Does K-Nearest Neighbour Algorithm Work?
Imagine a scatterplot of data points, some colored red and others blue.
When a new point appears, the algorithm finds its k nearest neighbors. If most nearby points are blue, the new one is labeled blue — simple majority rule!
Example:
If k = 3, and among the 3 closest neighbors:
- 2 are Apples
- 1 is Banana
→ The algorithm predicts Apple, since it’s the majority.
This visualizes how KNN uses proximity and similarity to make intelligent decisions.
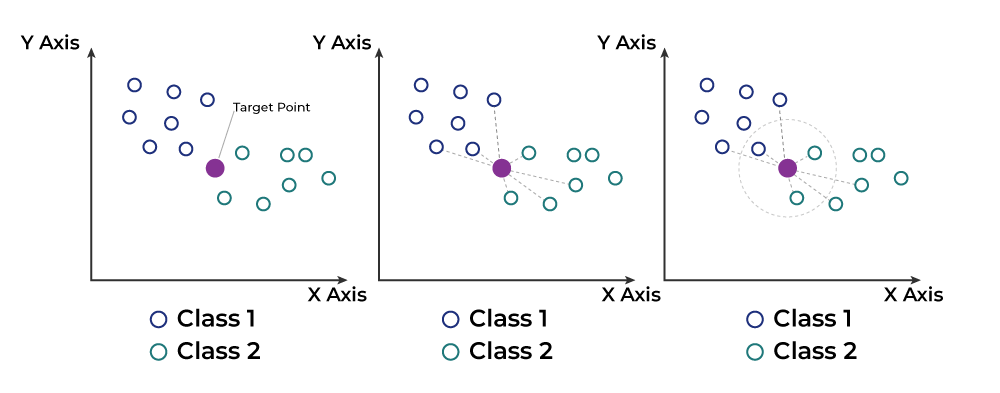
What Is “K” in K-Nearest Neighbour Algorithm?
The “k” in the algorithm defines how many neighbors should influence the prediction.
Choosing the right value of k is essential:
- Too small (e.g., k = 1): Overfits and becomes sensitive to noise.
- Too large (e.g., k = 20): May oversimplify patterns (underfitting).
Methods to Choose the Best k:
- Cross-Validation: Split data into folds and test different k values.
- Elbow Method: Plot error rate vs. k; choose where the curve bends (“elbow”).
- Odd Values: Use odd k to avoid ties in classification problems.
Distance Metrics Used in K-Nearest Neighbour Algorithm
To find the nearest neighbors, KNN uses mathematical distance formulas.
1. Euclidean Distance
The straight-line distance between two points:
2. Manhattan Distance
Also known as “taxicab” distance — the total distance along grid lines:
3. Minkowski Distance
A generalized form that includes both Euclidean (p=2) and Manhattan (p=1):
Step-by-Step Example of K-Nearest Neighbour Algorithm in Python
import numpy as np
from collections import Counter
def euclidean_distance(p, q):
return np.sqrt(np.sum((np.array(p) - np.array(q)) ** 2))
def knn_predict(X_train, y_train, x_test, k=3):
distances = []
for i in range(len(X_train)):
d = euclidean_distance(x_test, X_train[i])
distances.append((d, y_train[i]))
distances.sort(key=lambda x: x[0])
k_labels = [label for (_, label) in distances[:k]]
return Counter(k_labels).most_common(1)[0][0]
X_train = [[1, 2], [2, 3], [3, 4], [6, 7], [7, 8]]
y_train = ['A', 'A', 'A', 'B', 'B']
x_test = [4, 5]
print(knn_predict(X_train, y_train, x_test, k=3))
Output: A
Here, the model classifies the new point as Category A because most of its 3 nearest neighbors belong to that class.
Applications of K-Nearest Neighbour Algorithm
The K-Nearest Neighbour Algorithm is widely used across industries:
- Recommendation Systems: Suggest products by comparing similar users.
- Spam Detection: Identify spam emails by comparing with known spam patterns.
- Customer Segmentation: Group customers with similar purchasing behavior.
- Speech & Image Recognition: Match input data to known labeled examples.
Related Internal Link:
Learn about Neural Networks in Machine Learning
Read Scikit-Learn’s official KNN documentation
Advantages and Disadvantages of K-Nearest Neighbour Algorithm
Advantages
- Easy to implement and understand
- No training phase — just store data
- Works for both classification and regression
- Few parameters (k and distance metric)
Disadvantages
- Slow for large datasets (computes distance to all points)
- Sensitive to unscaled features
- Struggles in high-dimensional data
- Can overfit noisy datasets
Best Practices for Using K-Nearest Neighbour Algorithm
- Normalize or standardize your data before training
- Use PCA or feature selection to reduce dimensions
- Try weighted KNN (closer neighbors get higher influence)
- Use KD-Trees or Ball Trees for large datasets
- Experiment with different distance metrics
Conclusion
The K-Nearest Neighbour Algorithm stands out as one of the most intuitive, versatile, and easy-to-understand algorithms in the field of machine learning. Despite its conceptual simplicity, KNN delivers remarkably strong results for a wide range of classification and regression tasks, especially when dealing with datasets that are moderate in size and well-preprocessed.
At its core, the K-Nearest Neighbour Algorithm relies on the idea that similar data points exist close to one another in the feature space. By leveraging distance-based similarity measures such as Euclidean, Manhattan, or Minkowski distances, KNN identifies the most relevant neighboring data points to make predictions. This property makes it ideal for real-world applications like pattern recognition, recommendation systems, image classification, and customer segmentation.
However, the true effectiveness of the algorithm depends on several important factors:
- Choosing an optimal value of K through techniques like cross-validation or the elbow method.
- Scaling or normalizing features, since KNN is sensitive to different measurement units.
- Using dimensionality reduction (e.g., PCA) for high-dimensional datasets to enhance accuracy and efficiency.
- Applying efficient search structures such as KD-Trees or Ball Trees to reduce computation time on large datasets.
Moreover, KNN’s flexibility extends beyond just simple classification. It can also be adapted for regression problems, imputation of missing values, and even anomaly detection. Its ability to work directly with raw data without building a complex model makes it a great starting point for machine learning beginners and an effective baseline for performance comparison with more advanced algorithms.
In summary, the K-Nearest Neighbour Algorithm continues to be a cornerstone of practical machine learning. Its simplicity, interpretability, and adaptability make it a go-to choice for projects that demand accuracy with minimal complexity. When combined with proper data preprocessing and thoughtful parameter tuning, KNN can help build smart, data-driven, and efficient AI solutions that perform reliably in diverse domains.