
Table of Contents
- Introduction to K-Nearest Neighbor Algorithm
- How Does the K-Nearest Neighbor Algorithm Work?
- What Is “K” in K-Nearest Neighbor Algorithm?
- Distance Metrics in K-Nearest Neighbor Algorithm
- KD-Tree: Speeding Up KNN
- Step-by-Step KNN and KD-Tree Example
- Applications of K-Nearest Neighbor Algorithm and KD-Tree
- Advantages and Disadvantages
- Historical Context
- Conclusion
- Key Takeaways

Introduction to K-Nearest Neighbor Algorithm
The K-Nearest Neighbor Algorithm (KNN) is a cornerstone of supervised machine learning, renowned for its simplicity and versatility. Used primarily for classification and regression, KNN operates on the principle that similar data points cluster together in feature space. As a non-parametric, instance-based method, it makes no assumptions about data distribution and delays computation until prediction time, earning the moniker “lazy learner.”
This guide explores KNN, its optimization with KD-Trees, and practical applications, enriched with examples and visuals for clarity.
How Does the K-Nearest Neighbor Algorithm Work?
KNN predicts a new data point’s class or value by identifying its K closest neighbors in the training dataset and using their labels or values.
Step-by-Step Process
- Select K: Choose the number of neighbors (e.g., K=3).
- Calculate Distances: Measure the distance from the new point to all training points using a metric like Euclidean distance.
- Find K Nearest Neighbors: Sort distances and select the K smallest.
- Predict:
- Classification: Assign the majority class among neighbors.
- Regression: Compute the average value of neighbors.
- Output the Result.
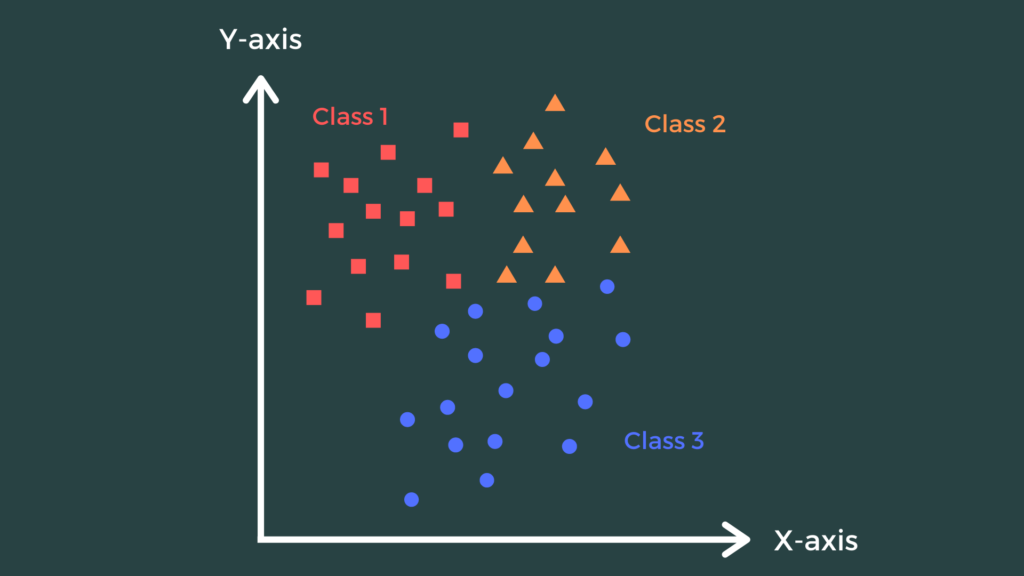
Visual Example
Imagine a 2D plot with points labeled as:
- Red diamonds (Category 1)
- Blue squares (Category 2)
A new point (hollow circle) is classified by checking its K=3 nearest neighbors. If two are blue squares, the point is predicted as Category 2.What Is “K” in K-Nearest Neighbor Algorithm?
K represents the number of neighbors considered for prediction. Choosing the right K is critical:
- Small K (e.g., K=1): Sensitive to noise, risks overfitting.
- Large K (e.g., K=20): Oversimplifies patterns, risks underfitting.
Methods to Choose K
- Cross-Validation: Test multiple K values by splitting data into training and validation sets.
- Elbow Method: Plot error vs. K and select the “elbow” where error stabilizes.
- Odd K Values: Preferred in binary classification to avoid ties.
Distance Metrics in K-Nearest Neighbor Algorithm
KNN relies on distance metrics to identify neighbors:
- Euclidean Distance: Straight-line distance.
- Manhattan Distance: Grid-based distance.
- Minkowski Distance: Generalizes Euclidean (p=2) and Manhattan (p=1).
KD-Tree: Speeding Up KNN
The KD-Tree (K-Dimensional Tree) is a binary search tree that organizes points in k-dimensional space, accelerating KNN’s neighbor search by pruning irrelevant regions.
Building a KD-Tree
Example Points: (2,3), (4,7), (5,4), (7,2), (8,1), (9,6)
- Root (x-split): Sort by x: (2,3), (4,7), (5,4), (7,2), (8,1), (9,6). Median: (7,2).
- Left Subtree (x<7): (2,3), (4,7), (5,4). Split by y, median: (5,4).
- Right Subtree (x>7): (8,1), (9,6). Split by y, median: (9,6).
KD-Tree Diagram:
(7,2) [x-split]
/ \
(5,4) [y-split] (9,6) [y-split]
/ \ /
(2,3) (4,7) (8,1)Nearest Neighbor Search with Backtracking
Query: (9,2)
- Traverse: Root (7,2) → x=9>7 → Right to (9,6) → y=2<6 → Left to (8,1).
Distance to (8,1): ( \sqrt{(9-8)^2 + (2-1)^2} = \sqrt{2} \approx 1.41 ). Best: 1.41. - Backtrack to (9,6): Axis dist |2-6|=4 > 1.41 → Skip right branch.
- Backtrack to (7,2): Axis dist |9-7|=2 > 1.41 → Skip left branch.
Result: Nearest neighbor = (8,1), distance = 1.41.
Case Requiring Exploration
Query: (6,5)
- Traverse: Root (5,4) → x=6>5 → Right to (9,6) → x=6<9 → Left to (8,1).
Distance to (8,1): ( \sqrt{20} \approx 4.47 ). - Backtrack to (9,6): Distance ( \sqrt{10} \approx 3.16 ). Best: 3.16. Axis dist |6-9|=3 < 3.16 → Explore right (empty).
- Backtrack to (5,4): Distance ( \sqrt{2} \approx 1.41 ). Best: 1.41. Axis dist |6-5|=1 < 1.41 → Explore left: (2,3) (4.47), (4,7) (2.83).
Result: Nearest neighbor = (5,4), distance = 1.41.
Step-by-Step KNN and KD-Tree Example
KNN Python Code
import numpy as np
from collections import Counter
def euclidean_distance(p, q):
return np.sqrt(np.sum((np.array(p) - np.array(q))**2))
def knn_predict(X_train, y_train, x_test, k=3):
distances = []
for i in range(len(X_train)):
d = euclidean_distance(x_test, X_train[i])
distances.append((d, y_train[i]))
distances.sort(key=lambda x: x[0])
k_labels = [label for _, label in distances[:k]]
return Counter(k_labels).most_common(1)[0][0]
X_train = [[1, 2], [2, 3], [3, 4], [6, 7], [7, 8]]
y_train = ['A', 'A', 'A', 'B', 'B']
x_test = [4, 5]
print(knn_predict(X_train, y_train, x_test, k=3)) # Output: AKD-Tree Search
For query (6,5) on points (2,3), (4,7), (5,4), (7,2), (8,1), (9,6), the KD-Tree prunes branches where axis distance exceeds the best distance, as shown above.
Applications of K-Nearest Neighbor Algorithm and KD-Tree
- KNN:
- Recommendation Systems: Suggest movies or products.
- Spam Detection: Classify emails.
- Customer Segmentation: Group similar behaviors.
- Speech/Image Recognition: Match patterns.
- KD-Tree:
- Nearest Neighbor Search: Speed up KNN.
- Range Search: GIS, database queries.
- Computer Graphics: Ray tracing, collision detection.
- Robotics: Path planning, SLAM.
Scikit-Learn KNN Documentation
Advantages and Disadvantages
KNN
Advantages:
- Simple and intuitive.
- No training phase.
- Multi-class and metric flexibility.
- Non-parametric.
Disadvantages:
- Slow for large datasets.
- Memory-intensive.
- Sensitive to scaling, noise, and high dimensions.
- K selection is critical.
KD-Tree
Advantages:
- Fast searches (O(log n)).
- Efficient range queries.
- Simple implementation.
- Ideal for static data.
Disadvantages:
- Poor in high dimensions.
- Imbalanced with skewed data.
- Costly updates.
- Limited to axis-aligned splits.

Historical Context
- KNN: Introduced by Thomas Cover and Peter Hart in 1967 (Paper: Nearest Neighbor Pattern Classification).
- KD-Tree: Introduced by Jon Louis Bentley in 1975 (Paper: Multidimensional Binary Search Trees Used for Associative Searching).
Conclusion
The K-Nearest Neighbor Algorithm is a versatile, intuitive tool for classification and regression, excelling in small to medium datasets with proper preprocessing. Its performance is enhanced by the KD-Tree, which optimizes neighbor searches through spatial partitioning. By mastering K selection, distance metrics, and KD-Tree mechanics, you can build robust, data-driven applications.
Key Takeaways
- KNN predicts based on K closest neighbors using distance metrics.
- KD-Tree accelerates KNN by pruning search space.
- Optimal K and feature scaling are critical for KNN accuracy.
- KD-Tree excels in low dimensions but struggles with high-dimensional data.
- Applications span recommendation systems, graphics, and robotics.