
Table of Contents
- Introduction to Machine Learning
- Why Train a Model in Python?
- Understanding the Model Training Process
- Step 1: Define the Problem
- Step 2: Collect and Prepare the Data
- Step 3: Choose the Right Algorithm
- Step 4: Split Data for Training and Testing
- Step 5: Train the Model
- Step 6: Evaluate the Model
- Step 7: Improve the Model Performance
- Step 8: Save and Deploy the Model
- Real-World Applications
- Common Mistakes Beginners Make
- Best Practices for Continuous Learning
- Final Thoughts
1. Introduction to Machine Learning
Training your first machine learning model in Python is one of the most rewarding experiences for anyone starting their journey in artificial intelligence and data science. It marks the transition from theory to hands-on practice — where you teach a computer to recognize patterns, make predictions, and solve real-world problems. This beginner-friendly guide will walk you through the entire process, from understanding the basics to evaluating your model’s performance — all without writing a single line of code.

2. Why Train a Model in Python?
Python has become the universal language of machine learning because of its simplicity, readability, and massive ecosystem of powerful libraries. Frameworks like scikit-learn, TensorFlow, and PyTorch allow developers to build and train models efficiently.
Some key reasons to use Python for model training include:
- Ease of learning: Even beginners can grasp Python syntax quickly.
- Rich libraries: Tools for data manipulation (NumPy, Pandas) and visualization (Matplotlib, Seaborn).
- Community support: A large and active community ensures continuous updates and solutions.
- Integration power: Easily integrates with data pipelines, cloud platforms, and APIs.
Python’s simplicity means you can focus on understanding the model training process instead of worrying about complex syntax.
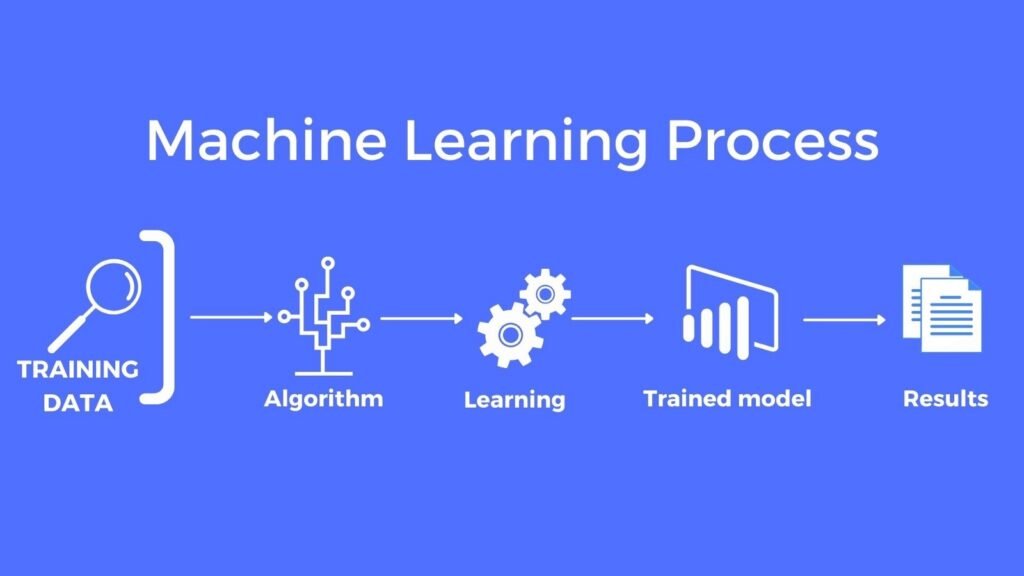
3. Understanding the Model Training Process
Training a machine learning model is not just about feeding data into an algorithm. It involves multiple well-defined steps:
- Defining the problem — identifying what you want the model to predict or classify.
- Collecting and preparing the data — ensuring clean, relevant, and structured datasets.
- Choosing an appropriate algorithm — selecting the model type that best fits the task.
- Splitting data — separating training and testing data to evaluate performance.
- Training the model — letting the algorithm learn from the data.
- Evaluating and improving — checking accuracy and fine-tuning parameters.
- Deployment — using the model in real-world applications.
Each stage contributes to how well your model performs and generalizes to unseen data.
4. Step 1: Define the Problem
The first step in training your first machine learning model in Python is defining a clear and measurable goal.
Ask yourself:
- What outcome do I want to predict?
- What kind of data is available?
- How will I measure success?
For instance, in healthcare, you might predict whether a patient has diabetes based on health metrics. In business, you might forecast sales or detect customer churn.
A well-defined problem statement lays the foundation for a successful model.
5. Step 2: Collect and Prepare the Data
The saying “garbage in, garbage out” holds true in machine learning. The quality of your model heavily depends on the quality of your data.
Here’s how you can prepare it:
- Data collection: Gather data from trusted sources — CSV files, APIs, or databases.
- Data cleaning: Remove duplicates, handle missing values, and correct inconsistencies.
- Feature selection: Choose variables that are relevant to your prediction goal.
- Data normalization: Scale features so that no single variable dominates the model.
In this stage, visualization tools like Matplotlib or Seaborn help uncover patterns and relationships between variables.
6. Step 3: Choose the Right Algorithm
Choosing the correct algorithm is like selecting the right tool for a job.
Some popular machine learning algorithms include:
- Linear Regression: Predicts continuous values (like house prices).
- Logistic Regression: Used for binary outcomes (yes/no decisions).
- Decision Trees: Simple models that split data into branches.
- Random Forests: Combine multiple trees for higher accuracy.
- K-Means Clustering: Groups data into clusters without labels.
The algorithm choice depends on your data type and problem goal — classification, regression, or clustering.
7. Step 4: Split Data for Training and Testing
To evaluate how well your model performs on new data, you need to divide your dataset into two parts:
- Training data (typically 70–80%) — used to train the model.
- Testing data (20–30%) — used to evaluate accuracy and performance.
This ensures your model doesn’t just memorize the training data but learns to generalize effectively.
8. Step 5: Train the Model
Now comes the most exciting part — training your first machine learning model in Python.
During training, the algorithm identifies relationships and patterns between the input features and the target output.
The model iteratively adjusts its parameters to minimize prediction errors. Over time, it learns to make accurate predictions on unseen data.
Remember: model training is about finding balance — overfitting means your model memorizes data; underfitting means it doesn’t learn enough.
9. Step 6: Evaluate the Model
Once trained, the model’s performance must be measured using evaluation metrics such as:
- Accuracy: How many predictions were correct.
- Precision and Recall: Useful for imbalanced datasets.
- F1 Score: A harmonic mean of precision and recall.
- Confusion Matrix: Shows true vs. false predictions visually.
These metrics reveal whether your model can be trusted to make predictions on real-world data.
10. Step 7: Improve Model Performance
Even a simple model can be improved through fine-tuning:
- Feature engineering: Creating new features from existing ones.
- Hyperparameter tuning: Adjusting model settings for optimal results.
- Cross-validation: Testing the model’s stability across different dataset splits.
- Ensemble learning: Combining multiple models for stronger predictions.
The goal is to minimize errors and improve accuracy without overfitting.
11. Step 8: Save and Deploy the Model
After evaluation, the next step is deployment. This means integrating the trained model into a real-world application — for example, predicting customer churn in a web dashboard or detecting spam emails in a mail server.
Tools like Flask, FastAPI, or Django allow you to deploy Python-based models easily. You can also use platforms like AWS SageMaker or Google AI Platform for production-level deployment.
12. Real-World Applications
Machine learning powers many of the digital experiences we rely on daily:
- Healthcare: Disease prediction, medical imaging, and diagnostics.
- Finance: Fraud detection and risk assessment.
- Retail: Recommendation systems and customer segmentation.
- Education: Personalized learning and performance analytics.
- Transportation: Route optimization and autonomous driving.
By training your first machine learning model in Python, you open doors to countless career opportunities and impactful applications.
13. Common Mistakes Beginners Make
Every beginner faces challenges. Here are common mistakes to avoid:
- Using data without cleaning or validation.
- Selecting the wrong algorithm for the task.
- Ignoring bias and imbalance in the dataset.
- Not evaluating the model properly.
- Overfitting due to too much training.
Understanding these pitfalls early helps you build stronger, more reliable models.
14. Best Practices for Continuous Learning
Machine learning is a field of constant evolution. To stay ahead:
- Follow tutorials and research papers.
- Experiment with different datasets.
- Join online communities and Kaggle competitions.
- Read documentation for tools like scikit-learn and TensorFlow.
- Practice regularly to strengthen your understanding.
Read More in detail How to train a good Model by IDM
Consistent experimentation will make you more confident and proficient with each model you build.
15. Final Thoughts
Congratulations on completing your journey to training your first machine learning model in Python!
You’ve learned the core process — from defining a problem and preparing data to training, evaluating, and deploying your model. Remember that this is just the beginning. The more datasets you explore and the more models you build, the better your understanding will become.
Machine learning thrives on curiosity and experimentation. Continue exploring, analyzing, and refining your models, and soon you’ll be ready to tackle advanced projects like predictive analytics, natural language processing, or computer vision.