
1. Data Sources Layer
The Data Sources Layer in a data warehouse architecture is the foundation of the system. It defines how raw data from operational systems, external APIs, spreadsheets, and logs enters the warehouse. Without reliable data sources, no data warehouse architecture can function effectively.
Types of Data Sources
1. Operational Databases (OLTP)
- Examples: Customer Relationship Management (CRM) systems, Enterprise Resource Planning (ERP) platforms, point-of-sale (POS) systems, HR management systems.
- Characteristics:
- Real-time, transactional data.
- Optimized for insert, update, and delete operations rather than complex queries.
- Continuously updated with live business activities (e.g., purchases, payments, reservations).
- Role in Data Warehousing: They provide the core transactional data—like sales, invoices, orders, and customer interactions—which forms the backbone of analytical insights.
2. External Sources
- Examples:
- Financial market data feeds (e.g., stock exchange APIs).
- Social media platforms (Twitter, Facebook, LinkedIn).
- IoT devices and sensors (smart meters, medical devices, GPS systems).
- Web services and third-party APIs.
- Characteristics:
- Often semi-structured or unstructured (JSON, XML, logs, sensor data).
- May include high-velocity streaming data.
- Require preprocessing and transformation to fit into the warehouse schema.
- Role in Data Warehousing: Brings contextual and real-world information (e.g., social sentiment, environmental conditions, competitor pricing) that complements internal business data.
3. Flat Files and Spreadsheets
- Examples: CSV files, Excel exports, text logs.
- Characteristics:
- Lightweight, easy to generate and share.
- Frequently used for ad hoc reporting or exporting data from legacy systems.
- Can contain historical records or manual entries that aren’t available in databases.
- Challenges:
- Data is often inconsistent, with missing values or formatting errors.
- Difficult to scale for large datasets.
- Role in Data Warehousing: Acts as a bridge for legacy or offline systems, especially when integrating data from small applications or external vendors.
4. Cloud Data Sources
- Examples: Amazon RDS, Google BigQuery, Microsoft Azure SQL Database, Snowflake.
- Characteristics:
- Hosted and managed in the cloud.
- Provide elasticity and scalability.
- Support both structured and semi-structured data (like JSON).
- Role in Data Warehousing: Many organizations are shifting their workloads to the cloud for cost efficiency and scalability, making cloud-based data sources critical for modern warehouses.
5. Logs and Machine Data
- Examples: Server logs, application logs, clickstream data, system monitoring tools.
- Characteristics:
- Semi-structured (log formats) or unstructured (free text).
- High volume and velocity.
- Role in Data Warehousing: Useful for user behavior analysis, fraud detection, and system performance monitoring.
Why the Data Sources Layer is Important
It sets the stage for ETL processes by supplying the raw material for data cleaning and integration.
It ensures comprehensive coverage of all business processes.
Provides raw, unaltered information that reflects reality before transformation.
The quality, variety, and timeliness of data sources directly impact the effectiveness of the warehouse.
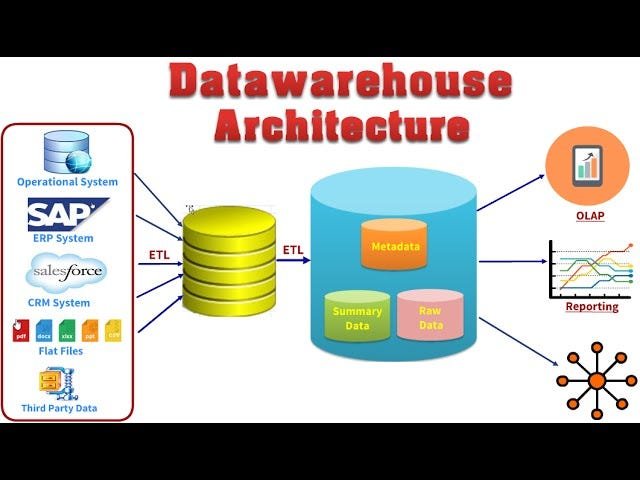
2. ETL Layer (Extract, Transform, Load)
The ETL process is at the heart of every data warehouse architecture. It extracts raw data, transforms it into consistent formats, and loads it into the storage layer.
A. Extract
- Function: Pull data from multiple sources.
- Challenges: Handling different formats, slow connections, full vs incremental extraction.
- Example: Extracting daily sales data from ERP.
B. Transform
- Function: Clean and standardize data.
- Key Operations:
- Data Cleaning → remove duplicates, handle missing values.
- Data Transformation → convert data types, normalize units.
- Data Aggregation → summarize (e.g., monthly sales).
- Data Integration → merge from multiple sources.
- Example: Standardizing dates to
YYYY-MM-DD, converting currencies to USD.
Read this article for more details
C. Load
- Function: Store processed data into the warehouse.
- Types of Loading:
- Full Load: Initial bulk load.
- Incremental Load: Only new/updated records (regular).
Goal: Keep the warehouse up-to-date and accurate.
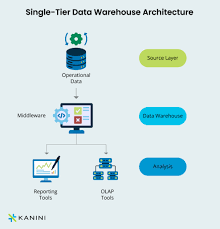
3. Data Storage Layer (The Warehouse)
This is the central repository where cleaned, integrated, and historical data resides.
Key Concepts
- Fact Tables
- Quantitative measures (sales, revenue, profit).
- Linked to dimensions via foreign keys.
- Dimension Tables
- Descriptive attributes (customer, product, time, location).
- Provide context for analysis.
Schema Types
- Star Schema → Simple, faster queries (fact table at center with dimensions).
- Snowflake Schema → Normalized, less redundancy but more complex queries.
Purpose: Store data in a way optimized for analysis (not transactions).
4. Data Access Layer
This is how end-users interact with the warehouse.
Components
- OLAP (Online Analytical Processing)
- Operations:
- Slice → subset of data (e.g., sales in January).
- Dice → specific subcube (e.g., product X in region Y).
- Drill-down / Drill-up → navigate summary vs detailed data.
- Operations:
- Reporting Tools / Dashboards
- Examples: Power BI, Tableau, QlikView.
- Converts raw data into visual insights.
- Query Tools / Ad-hoc Reporting
- Direct SQL queries for analysts.
Purpose: Provide decision support and fast analytics.
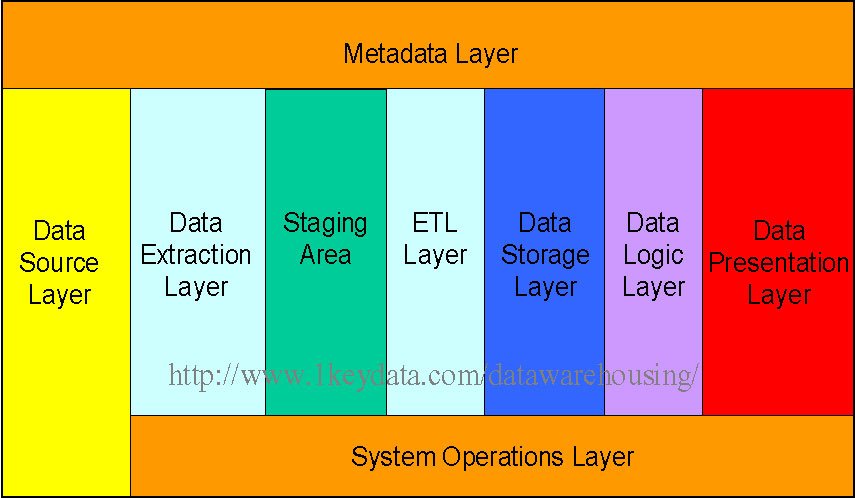
5. Metadata Layer
Metadata = “data about data.” It describes the contents and processes of the warehouse.
Types of Metadata
- Technical Metadata → table structures, ETL rules.
- Business Metadata → definitions, meanings, business rules.
- Operational Metadata → ETL logs, schedules, data lineage.
Purpose: Improves understanding, governance, and auditing of data.
6. Management & Control Layer
This layer ensures the warehouse runs smoothly and securely.
Functions
- ETL Scheduling & Monitoring → Automates workflows, tracks failures.
- Data Quality Management → Ensures accuracy and completeness.
- Security & Access Control → Defines who can view/modify data.
- Performance Management → Optimizes queries, indexing, and storage.
Purpose: Maintain integrity, reliability, and efficiency.
Read this artile for more details
7. Quick Summary Table
| Layer / Term | Function |
|---|---|
| Data Sources | Collect raw data from multiple systems |
| ETL (Extract) | Pull data from sources |
| ETL (Transform) | Clean, standardize, aggregate, integrate |
| ETL (Load) | Store processed data into warehouse |
| Data Warehouse (Storage) | Store organized historical data |
| Fact Table | Quantitative measures (sales, revenue) |
| Dimension Table | Descriptive context (customer, product, time) |
| OLAP / Reporting | Analyze and visualize data |
| Metadata | Info about structure, definitions, and processes |
| Management & Control | Monitor, secure, and maintain operations |
Conclusion
In today’s data-driven world, having a well-structured Data Warehouse Architecture is critical for turning raw information into valuable business insights. By combining data sources, ETL processes, centralized storage, metadata management, and powerful access layers, organizations can ensure data accuracy, consistency, and accessibility. A strong data warehouse architecture not only supports better decision-making but also provides a scalable foundation for advanced analytics, reporting, and business intelligence. Investing in the right architecture means investing in the future growth and success of any organization.